Monday, July 14th, 2014
In my previous post I showed how to generate good looking charts with Gnuplot. Those were simple bar charts with a single bar. In this post I want to show you how to plot bar charts with multiple bars. Such charts take multiple columns of data and plot them grouped in the chart. We’ll be working with the following data:
2013-4 271467 250500
2013-5 217188 198030
2013-6 192770 163000
2013-7 242761 233000
2013-8 192893 189603
2013-9 209139 154500
2013-10 235128 202300
2013-11 264841 250070
2013-12 290258 270699
2014-1 249561 209000
2014-2 225669 185000
2014-3 247809 212000
We will re-use the Gnuplot settings from the previous post. In the previous post, we used the “plot … with boxes” method of plotting bar charts. To plot a second set of data, we just add another plotting rule after the first one:
plot "registrations.dat" using 2:xticlabels(1) with boxes lt rgb "#406090",\
"" using 3 lt rgb "#40FF00"
We don’t need to specify a data file. Gnuplot will simply reuse the first one. We define the third column and set a different color for the second set of data. This is what it produces:
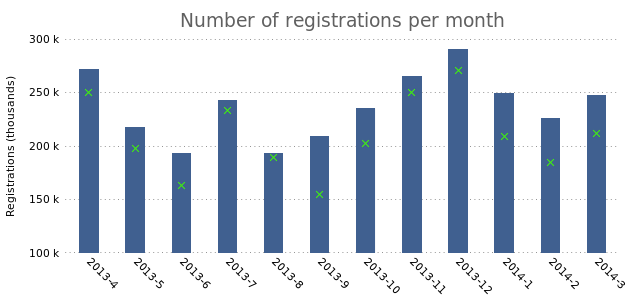
As you can see, it plots the third column of data as “X”s on top of the current bar. If we add the “with boxes” option to the second plotting rule, we’ll see that it creates overlapping bars:
plot "registrations.dat" using 2:xticlabels(1) with boxes lt rgb "#406090",\
"" using 3 with boxes lt rgb "#40FF00"
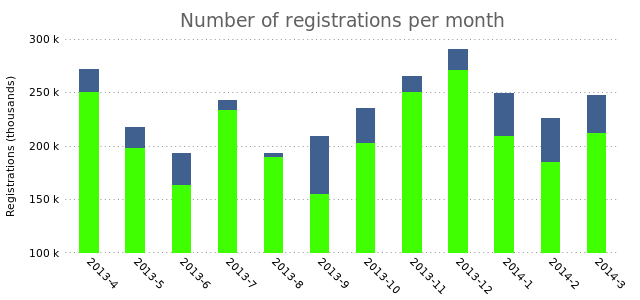
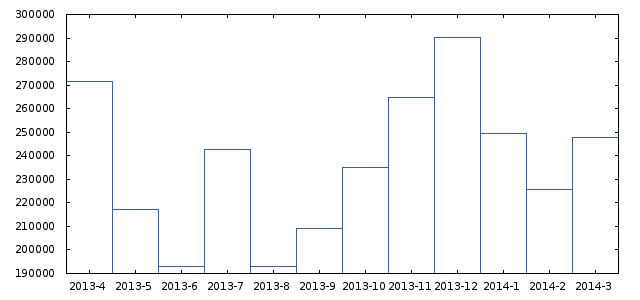
While that could be a useful way to represent your data, what if you want the bars to appear next to each other? Now we run into a problem. The plotting method we use can’t deal with that. We need to plot our data as a histogram. Let’s first see how that works with a single bar:
set boxwidth 1
set style data histograms
plot "registrations.dat" using 2:xtic(1) lt rgb "#406090"
We change the boxwidth to “1” (from 0.6 in in the previous post). We then set the plotting style to “histograms”. The rest remains the same.
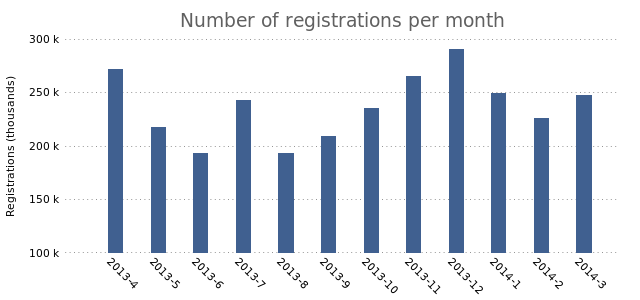
This looks a lot like the final result from the previous post. Now we’re all set to start plotting multiple bars. Let’s add a second plot:
set style data histograms
plot "registrations.dat" using 2:xtic(1) lt rgb "#406090",\
"" using 3 lt rgb "#40FF00"
This results in the following chart:
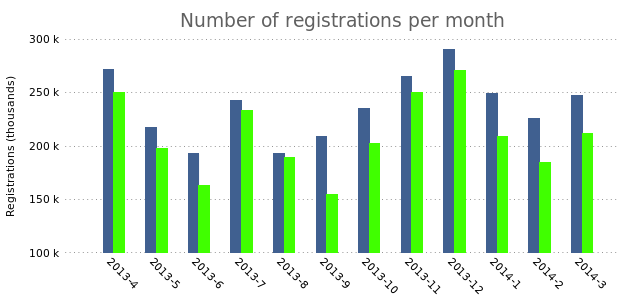
The bars slightly overlap, which we can fix by changing the box width to a slightly smaller value:
set boxwidth 0.8
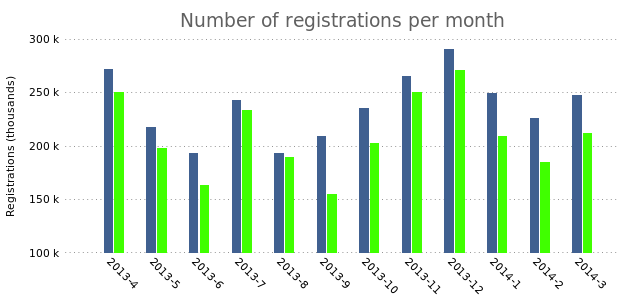
In charts with multiple columns of data it would be smart to add the legend that we removed in the previous post.
#set nokey
plot "registrations.dat" using 2:xtic(1) title "Total" lt rgb "#406090",\
"" using 3 title "From web" lt rgb "#40FF00"
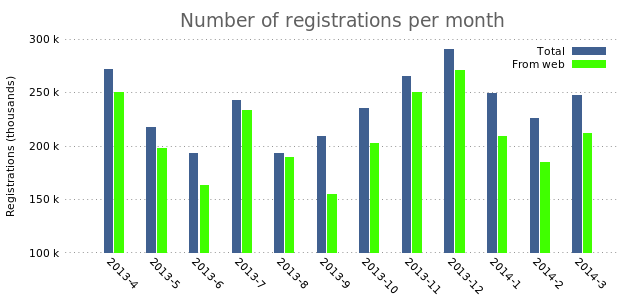
There you have it. Multiple bars. Adding even more bars is a simple as simply adding another plot.
Update: Thanks to Mario Domenech Goulart for spotting that the link to the previous GNUplot post was broken!
Saturday, July 12th, 2014
Gnuplot is a tool for plotting graphs. It was originally created to allow scientists and students to visualize mathematical functions and data interactively, but has grown to support many non-interactive uses such as web scripting. It is excellent for generating all kinds of charts. Unfortunately, the defaults for Gnuplot don’t generate very appealing charts:
set terminal png size 640,300
set output "1.png"
plot "registrations.dat" using 2:xticlabels(1) with boxes lt rgb "#406090"
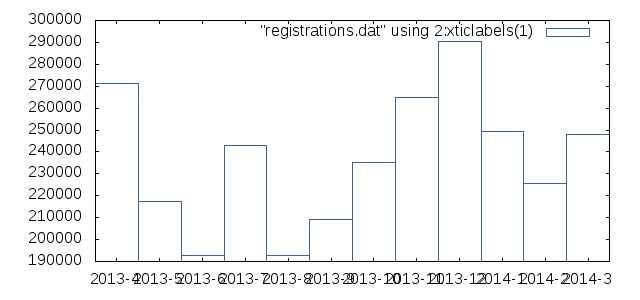
That’s uh.. pretty ugly. Maybe that looks great if you’re going for the whole sciency look, but we want something better. Let’s fix ‘r up!
The first things we’ll do is change that ugly font to something better and get rid of the text inside the graph.
# Output to PNG, with Verdana 8pt font
set terminal png nocrop enhanced font "verdana,8" size 640,300
# Don't show the legend in the chart
set nokey
Here’s what it looks like now. Slightly better:
Let’s do something about those horrid bars. We’ll make them thinner and fill them in.
# Thinner, filled bars
set boxwidth 0.4
set style fill solid 1.00
Okay. Now we’ll do something about the labels. We’ll add a title to the chart, set a label on the Y-axis and make the values on the Y-axis better readable.
# Set a title and Y label. The X label is obviously months, so we don't set it.
set title "Number of registrations per month"
set ylabel "Registrations (thousands)"
# Rotate X labels and get rid of the small striped at the top (nomirror)
set xtics nomirror rotate by -45
# Show human-readable Y-axis. E.g. "100 k" instead of 100000.
set format y '%.0s %c'
It now looks like this:
Now we’re getting somewhere! One of the rules of creating nice charts is “less is more”. This means you should remove everything that is not vital to getting your message across. See the little stripes on the Y-axis on the left and right side of the chart? Useless. Border? Useless. Let’s get rid of them:
# Replace small stripes on the Y-axis with a horizontal gridlines
set tic scale 0
set grid ytics
# Remove border around chart
unset border
Much nicer. Let’s do a few small optimizations and we’ll be done. We increase the title’s font size and color, change the range of the Y-axis from 190k-300k to 100k-300k and make the horizontal grid lines a little less pronounced.
# Set a title and Y label. The X label is obviously months, so we don't set it.
set title "Number of registrations per month" font ",14" tc rgb "#606060"
# Lighter grid lines
set grid ytics lc rgb "#C0C0C0"
# Manual set the Y-axis range
set yrange [100000 to 300000]
The final result:
One final improvement we can make is changing the rendering engine from the default to the Cairo engine. Whether this works for you depends on if your Gnuplot was compiled with Cairo enabled. The Cairo engine does a much better job of anti-aliasing the chart, which is especially important for line charts. Here’s how to enable rendering with the Cairo engine:
set terminal pngcairo nocrop enhanced font "verdana,8" size 640,300
set grid ytics lc rgb "#505050"
We also had to modify the grid color, because it was barely distinguishable in the Cairo render. This is what it looks like:
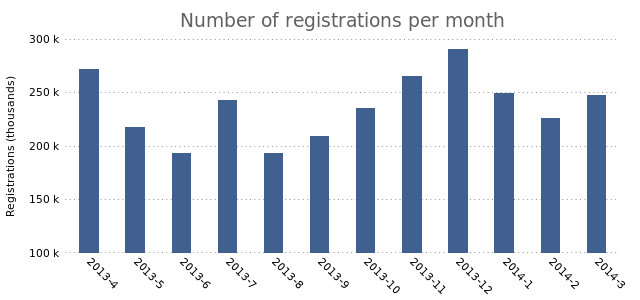
Here’s the full GnuPlot file:
# Output to PNG, with Verdana 8pt font
set terminal pngcairo nocrop enhanced font "verdana,8" size 640,300
# Don't show the legend in the chart
set nokey
# Thinner, filled bars
set boxwidth 0.4
set style fill solid 1.00
# Set a title and Y label. The X label is obviously months, so we don't set it.
set title "Number of registrations per month" font ",14" tc rgb "#606060"
set ylabel "Registrations (thousands)"
# Rotate X labels and get rid of the small stripes at the top (nomirror)
set xtics nomirror rotate by -45
# Show human-readable Y-axis. E.g. "100 k" instead of 100000.
set format y '%.0s %c'
# Replace small stripes on the Y-axis with a horizontal gridlines
set tic scale 0
set grid ytics lc rgb "#505050"
# Remove border around chart
unset border
# Manual set the Y-axis range
set yrange [100000 to 300000]
set output "6.png"
plot "registrations.dat" using 2:xticlabels(1) with boxes lt rgb "#406090"
The data used (registrations.dat):
2013-4 271467
2013-5 217188
2013-6 192770
2013-7 242761
2013-8 192893
2013-9 209139
2013-10 235128
2013-11 264841
2013-12 290258
2014-1 249561
2014-2 225669
2014-3 247809
You can save the Gnuplot directives to a file called “base.gnuplot” and include it in other files to get the desired result for multiple charts:
load "base/charts/base.gnuplot"
Gnuplot has a huge number of options and abilities. Here’s a few resources that show how Gnuplot can be used:
I hope you found this post useful.
Monday, June 16th, 2014
If you want to upload a file by commandline via SFTP, you may end up on this StackOverflow page. The answer there is WRONG. Those are not using the SFTP subsystem, they use SSH and process output redirection. Using scp will result in an error if the server only allows the SFTP subsystem:
This service allows sftp connections only.
Instead, use this:
$ echo "put system.log" | sftp upload@sftp.example.com:logs/
Connected to example.com.
Changing to: /home/upload/logs/
sftp> put system.log
Uploading system.log to /home/upload/logs/system.log
system.log 100% 61 0.1KB/s 00:00
to upload a local file “system.log” to the remote SFTP host in the logs/ directory. You can also use wildcards.
The above command generates some output you may not want. In that case you can use the -q switch and redirect output to /dev/null:
$ echo "put system.log" | sftp -q upload@sftp.example.com:logs/ > /dev/null
Connected to example.com
As you can see, this still generates a little output. To fix this, we have to use batch mode:
$ cat batch.txt
put *.log
$ sftp -q -b batch.txt upload@sftp.example.com:logs/ > /dev/null
$
Batch mode requires the use of a passwordless private key. If you don’t want to load it into a key agent (for automated scripts, etc), you can use the “-o IdentityFile” option:
$ sftp -q -b batch.txt -o IdentityFile=key.rsa upload@sftp.example.com:logs/ > /dev/null
Friday, May 9th, 2014
By chance I stumbled upon an article about databases and how they scale. It’s a great read and does an excellent job describing the various stengths and weaknesses regarding different kinds of scaling for databases. Especially the images really capture the essence. 
Monday, March 31st, 2014
Git is a great tool, but its documentation leaves much to be desired at times. Bitbucket’s documentation doesn’t fare much better. Commands mentioned in its wiki often don’t work as advertised. The fact that git’s commands are often incredibly counter-intuitive, incomplete and at times simply wrong doesn’t help either. So while you can get far with git by just copying random (and again, wrong more often than not) commands from Stack Overflow, there comes a time where you actually have to learn how it works.
In my case, I had a very simple request. Somebody opened a pull request from a fork of one of my projects and I simply wanted to test that change before I merged it. Bitbucket’s wiki was unhelpful as the commands it listed simply didn’t work. Here’s how I got it to work in a way that actually makes sense.
What we’ll be doing
We’ll be working with two repositories here:
- The main repository called “test“, owned by user “fboender”
- The forked repository called “test-fork“, also owned by user “fboender”. Normally the forked repository wouldn’t be owned by the same person, but in Bitbucket you can fork your own repositories, and this makes for a good test.
We have:
- A pull request containing two commits on a branch called ‘bugfix‘ on the forked ‘test-fork‘ repository.
- We want to review these commits, test them and either merge them into our main repository ‘test‘ or reject them.
We’ll perform the following steps:
- Prepare the working directory
- Retrieve the remote changes (commits) for the pull request to our local clone
- Review the changes
- Either reject or accept (merge) the changes
- Push the accepted changes (merge / pull request) back to Bitbucket.
Prepare the working directory
Make sure you have no uncommited changes in your working dir:
$ git status
# On branch master
nothing to commit, working directory clean
If there are uncommited changes, either commit them or get rid of them.
Retrieve remote changes
Next we’ll retrieve the remote changes introduced by the pull request. We don’t want those changes to affect our local repository in any way. We just want to retrieve them so we can review the changes. To do so, we’ll need to know the source from where we want to fetch the changes. This is what the pull requests looks like in the Bitbucket interface:
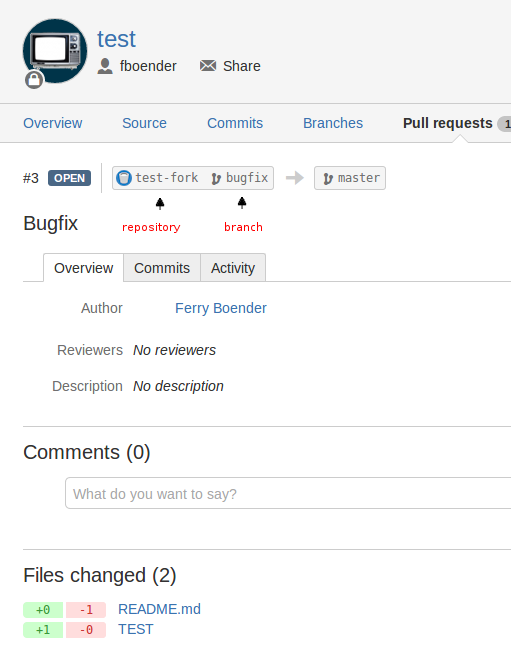
If you hover your mouse over the branch, you can see the URL for the source of the merge request. In this case: https://bitbucket.org/fboender/test-fork/branch/bugfix.
We’ll use git’s fetch command to fetch the objects (commits) in the pull request. The format for the fetch command in this case is:
git fetch <repository> <refspec>
For our pull request the repository is https://bitbucket.org/fboender/test-fork. The refspec can be almost anything really. A commit, a branch name, whatever. In this case we’ll use the branch name, which is bugfix, as you can infer from the URL above.
$ git fetch https://bitbucket.org/fboender/test-fork bugfix
remote: Counting objects: 13, done.
remote: Compressing objects: 100% (7/7), done.
remote: Total 8 (delta 2), reused 0 (delta 0)
Unpacking objects: 100% (8/8), done.
From https://bitbucket.org/fboender/test-fork
* branch bugfix -> FETCH_HEAD
Git has now retrieved the commits and put them in our local index. If you wouldn’t know better, you wouldn’t be able to find them though! The commits are there, but they’re not part of any branch or anytihng. To get to the changes, we’ll need to use the last commit id (ad38a9b) or the (temporary) FETCH_HEAD ref, which git has created for us.
Review the changes
Okay, so we want to do various reviews of the changes. First let’s look at the changes between our current branch (master) and the new changes:
$ git diff master FETCH_HEAD
diff --git a/README.md b/README.md
index 08cdfb4..cc11a2f 100644
--- a/README.md
+++ b/README.md
@@ -6,4 +6,3 @@ About
This is a test repository, for testing.
-TEST in sub
diff --git a/TEST b/TEST
index 3fb25cd..bc440ae 100644
--- a/TEST
+++ b/TEST
@@ -1 +1,2 @@
BLA
+FOO
Looks good. Two commits that ammend the TEST file and update the README.md file. Now perhaps we want to run some tests on the new changes before accepting and merging the pull request. To get to the actual changes, we can checkout a refspec. In this case either the FETCH_HEAD refspec that git helpfully created for us, or we can use the last commit in the pull request: ad38a9b. We’ll be using FETCH_HEAD. Remember that this refspec is temporary! If you do a new fetch (that includes git pull and various other commands), the FETCH_HEAD could have changed.
$ git checkout FETCH_HEAD
Note: checking out 'FETCH_HEAD'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD is now at ad38a9b... Updated README
Okay, seems to have worked. The git log shows the commits:
$ git log
commit ad38a9b402eac93995902560292697245418a192
Author: Ferry Boender <ferry.boender@electricmonk.nl>
Date: Mon Mar 31 19:37:26 2014 +0200
Updated README
commit c538608863dd9dda276edf5adcad9e0f2ef9f9ed
Author: Ferry Boender <ferry.boender@electricmonk.nl>
Date: Mon Mar 31 19:37:11 2014 +0200
Ammended TEST file
commit f8d3d31ea1195e2cb1c0631d95c2b33c313b60b8
Author: Ferry Boender <ferry.boender@gmail.com>
Date: Mon Mar 31 17:36:23 2014 +0000
Created new branch bugfix
We can now run some tests on the working directory, further inspect the changes, etc.
Reject the changes
If you’re not satisfied with the changes, you can just check out the original branch:
$ git checkout master
Warning: you are leaving 3 commits behind, not connected to
any of your branches:
ad38a9b Updated README
c538608 Ammended TEST file
f8d3d31 Created new branch bugfix
If you want to keep them by creating a new branch, this may be a good time
to do so with:
git branch new_branch_name ad38a9b
Switched to branch 'master'
Note that the commits are still in your index. You’ve just chosen not to do anything with them. You can now reject the pull request in Bitbucket’s interface.
Accept the changes
If you’re satisfied that the changes made work properly and want to keep the changes from the pull request, you can merge them into a branch. In this case, we’ll merge them directly into the master branch.
First, we reattach our HEAD to the correct branch:
$ git checkout master
Next, we merge in the changes:
$ git merge FETCH_HEAD
Updating 2f6ecbf..ad38a9b
Fast-forward
README.md | 1 -
TEST | 1 +
2 files changed, 1 insertion(+), 1 deletion(-)
Finally, we push the changes to Bitbucket. This will automatically accept the pull request on Bitbucket.
$ git push
Counting objects: 13, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6/6), done.
Writing objects: 100% (8/8), 873 bytes | 0 bytes/s, done.
Total 8 (delta 2), reused 1 (delta 1)
To git@bitbucket.org:fboender/test.git
2f6ecbf..ad38a9b master -> master
The changes have now been pushed to the origin repository and the pull request has been accepted automatically by Bitbucket.
That’s it, we’re done!
Make “changes” to the pull request
Suppose you find the pull request is largely okay, however it’s missing some small things. Maybe the developer who forked didn’t update the documentation to reflect the changes he made? Such a hypothetical situation would of course never happen in real life, but let’s suppose it does! How do you go about fixing the pull request which still properly accepting it? Here’s how:
We’ve fetched the remote changes and are now inspecting them in our working dir:
$ git fetch https://bitbucket.org/fboender/test-fork bugfix
...
$ git checkout FETCH_HEAD
...
Everything is almost correct, but we need to make some minor changes before accepting the merge request. We can now simply create a new commit in the detached head state:
$ echo "QUUX" >> TEST
$ git add TEST
$ git commit -m "Fixed missing ammend"
[detached HEAD ab11d9a] Fixed missing ammending
1 file changed, 1 insertion(+)
This gives us a new commit id “ab11d9a” which we can use to merge both the commits from the pull request as well as the new commit:
$ git checkout master
Warning: you are leaving 2 commits behind, not connected to
any of your branches:
ab11d9a Fixed missing ammending
e761f43 Ammended TEST some more
$ git merge ab11d9a
Updating ad38a9b..ab11d9a
Fast-forward
TEST | 2 ++
1 file changed, 2 insertions(+)
$ git push
The merge request will now automatically be accepted and our additional commit will also be pushed to the main repository. Note that this doesn’t actually makes any changes to the pull request. It’s just an additional commit that you’re merging in at the same time as the commits from the pull request. This is useful to prevent broken code on branches.
Monday, March 31st, 2014
I’ve just released version 0.6 of my Vim bexec plugin.
Bexec is a Vim plugin that allows the user to execute the current buffer if it contains a script with a shebang (#!/path/to/interpreter) on the first line or if the default interpreter for the script’s type is known by Bexec. The output of the script will be grabbed and displayed in a separate buffer.
New in this version:
- Support (fix) for Windows support. (by mohd-akram)
You can get the new version (as a Vimball) from:
Friday, February 14th, 2014
I’ve just released bbcloner v1.3. bbcloner creates mirrors of your public and private Bitbucket Git repositories and wikis. It also synchronizes already existing mirrors. Initial mirror setup requires you manually enter your username/password. Subsequent synchronization of mirrors is done using Deployment Keys.
This release features the following changes:
- Support for updating over https (patch by msboom)
Sunday, January 12th, 2014
As can be read in this article, I was in need of a method to quickly drop all indexes (except primary keys) from a MySQL database. After googling around a bit and being astonished that apparently no-one had written such a thing yet, I wrote the script that can be seen in that article.
Unfortunately, that script wasn’t very good, so I decided to do a cleaner better implementation of it. The result is my_indexr, which spits out SQL commands to drop and recreate indexes on a database. Other features include:
- Process only certain tables
- Process non-primary or both normal and primary indexes
- Correctly handles:
- Primary key indexes
- Compound key / multi-column indexes
- Index types (BTREE, etc)
- Prefix lengths
- Auto_increment columns, which MUST be a key (my_indexr skips indexes with these columns in them)
There may still be some edge-cases that are not properly handled by my_indexr. If you encouter one, please let me know.
You can download my_indexr from its Bitbucket page.
This is what its output looks like:
$ ./indexr.py -u root -p mydb
DROP INDEX `location` ON `idx_tst_innodb_basic`;
DROP INDEX `name_age` ON `idx_tst_innodb_basic`;
DROP INDEX `email` ON `idx_tst_innodb_basic`;
DROP INDEX `PRIMARY` ON `idx_tst_innodb_compkey`;
CREATE INDEX `location` USING BTREE ON `idx_tst_innodb_basic` (`location_id`);
CREATE INDEX `name_age` USING BTREE ON `idx_tst_innodb_basic` (`name`(40),`age`);
CREATE UNIQUE INDEX `email` USING BTREE ON `idx_tst_innodb_basic` (`email`);
ALTER TABLE `idx_tst_innodb_compkey` ADD PRIMARY KEY (`last_name`,`first_name`);
Monday, December 16th, 2013
There’s a free download available of “Think Bayes – Bayesian Statistics in Python” over at it-ebooks.info. A small excerpt from the book:
The premise of this book, and the other books in the Think X series, is that if you know
how to program, you can use that skill to learn other topics.
Most books on Bayesian statistics use mathematical notation and present ideas in terms
of mathematical concepts like calculus. This book uses Python code instead of math,
and discrete approximations instead of continuous mathematics. As a result, what
would be an integral in a math book becomes a summation, and most operations on
probability distributions are simple loops.
Wednesday, November 6th, 2013
I recently had to perform some bulk updates on semi-large tables (3 to 7 million rows) in MySQL. I ran into various problems that negatively affected the performance on these updates. In this blog post I will outline the problems I ran into and how I solved them. Eventually I managed to increase the performance from about 30 rows/sec to around 7000 rows/sec. The final performance was mostly CPU bound. Since this was on a VPS with only limited CPU power, I expect you can get better performance on some decently outfitted machine/VPS.
The situation I was dealing with was as follows:
-
About 20 tables, 7 of which were between 3 and 7 million rows.
-
Both MyISAM and InnoDB tables.
-
Updates required on values on every row of those tables.
-
The updates where too complicated to do in SQL, so they required a script.
-
All updates where done on rows that were selected on just their primary key. I.e. WHERE id = …
Here are some of the problems I ran into.
Python’s MySQLdb is slow
I implemented the script in Python, and the first problem I ran into is that the MySQLdb module is slow. It’s especially slow if you’re going to use the cursors. MySQL natively doesn’t support cursors, so these are emulated in Python code. One of the trickiest things is that a simple SELECT * FROM tbl will retrieve all the results and put them in memory on the client. For 7 million rows, this quickly exhausts your memory. Real cursors would fetch the result one-by-one from the database so that you don’t exhaust memory.
The solution here is to not use MySQLdb, but use the native client bindings available with import mysql.
LIMIT n,m is slow
Since MySQL doesn’t support cursors, we can’t mix SELECT and UPDATE queries in a loop. Thus we need to read in a bunch of rows into memory and update in a loop afterwards. Since we can’t keep all the rows in memory, we must read in batches. An obvious solution for this would be a loop such as (pseudo-code):
offset = 0
size = 1000
while True:
rows = query('SELECT * FROM tbl LIMIT :offset, :size"
for row in rows:
# do some updates
if len(rows) < size:
break
offset += size
This would use the LIMIT to read the first 1000 rows on the first iteration of the loop, the next 1000 on the second iteration of the loop. The problem is: in MySQL this becomes linearly slower for higher values of the offset. I was already aware of this, but somehow it slipped my mind.
The problem is that the database has to advance an internal pointer forward in the record set, and the further in the table you get, the longer that takes. I saw performance drop from about 5000 rows/sec to about 100 rows/sec, just for selecting the data. I aborted the script after noticing this, but we can assume performance would have crawled to a halt if we kept going.
The solution is to use the order by the primary key and then select everything we haven’t processed yet:
size = 1000
last_id = 0
while True:
rows = query('SELECT * FROM tbl WHERE id > :last_id ORDER BY id LIMIT :size')
if not rows:
break
for row in rows:
# do some updates
last_id = row['id']
This requires that you have an index on the id field, or performance will greatly suffer again. More on that later.
At this point, +SELECT+s were pretty speedy. Including my row data manipulation, I was getting about 40.000 rows/sec. Not bad. But I was not updating the rows yet.
Connection settings
The next things I did is some standard tricks to speed up bulk updates/inserts by disabling some foreign key checks and running batches in a transaction. Since I was working with both MyISAM and InnoDB tables, I just mixed optimizations for both table types:
db.query('SET autocommit=0;')
db.query('SET unique_checks=0; ')
db.query('SET foreign_key_checks=0;')
db.query('LOCK TABLES %s WRITE;' % (tablename))
db.query('START TRANSACTION;')
# SELECT and UPDATE in batches
db.query('COMMIT;')
db.query('UNLOCK TABLES')
db.query('SET foreign_key_checks=1;')
db.query('SET unique_checks=1; ')
db.query('SET autocommit=1;')
I must admit that I’m not sure if this actually increased performance at all. It is entirely possible that this actually hurts performance instead. Please test this for yourselves if you’re going to use it. You should also be aware that some of these options bypass MySQL’s data integrity checks. You may end up with invalid data such as invalid foreign key references, etc.
One mistake I did make was that I accidentally included the following in an early version of the script:
db.query('ALTER TABLE %s DISABLE KEYS;' % (tablename))
Such is the deviousness of copy-paste. This option will disable the updating of non-unique indexes while it’s active. This is an optimization for MyISAM tables to massively improve performance of mass INSERTs, since the database won’t have to update the index on each inserted row (which is very slow). The problem is that this also disables the use of indexes for data retrieving, as noted in the MySQL manual:
While the nonunique indexes are disabled, they are ignored for statements such as SELECT and EXPLAIN that otherwise would use them.
That means update queries such as UPDATE tbl SET key=value WHERE id=1020033 will become incredibly slow, since they can no longer use indexes.
MySQL server tuning
I was running this on a stock Ubuntu 12.04 installation. MySQL is basically completely unconfigured out of the box on Debian and Ubuntu. This means that those 16 GBs of memory in your machine will go completely unused unless you tune some parameters. I modified /etc/mysql/my.cnf and added the following settings to improve the speed of queries:
[mysqld]
key_buffer = 128M
innodb_buffer_pool_size = 3G
The key_buffer setting is a setting for MyISAM tables that determines how much memory may be used to keep indexes in memory. The equivalent setting for InnoDB is innodb_buffer_pool_size, except that the InnoDB setting also includes table data.
In my case the machine had 4 GB of memory. You can read more about the settings on these pages:
Don’t forget to restart your MySQL server.
Dropping all indexes except primary keys
One of the biggest performance boosts was to drop all indexes from all the tables that needed to be updates, except for the primary key indexes (those on the id fields). It is much faster to just drop the indexes and recreate them when you’re done. This is basically the manual way to accomplish what we hoped the ALTER TABLE %s DISABLE KEYS would do, but didn’t.
UPDATE: I wrote a better script which is available here.
Here’s a script that dumps SQL commands to drop and recreate indexes for all tables:
#!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
# DANGER WILL ROBINSON, READ THE important notes BELOW
#!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
import _mysql
import sys
mysql_username = 'root'
mysql_passwd = 'passwd'
mysql_host = '127.0.0.1'
dbname = 'mydb'
tables = sys.argv[1:]
indexes = []
db = _mysql.connect(user=mysql_username, passwd=mysql_passwd, db=dbname)
db.query('SHOW TABLES')
res = db.store_result()
for row in res.fetch_row(maxrows=0):
tablename = row[0]
if not tables or tablename in tables:
db.query('SHOW INDEXES FROM %s WHERE Key_name != "PRIMARY"' % (tablename))
res = db.store_result()
for row_index in res.fetch_row(maxrows=0):
table, non_unique, key_name, seq_in_index, column_name, \
collation, cardinality, sub_part, packed, null, index_type, \
comment, index_comment = row_index
indexes.append( (key_name, table, column_name) )
for index in indexes:
key_name, table, column_name = index
print "DROP INDEX %s ON %s;" % (key_name, table)
for index in indexes:
key_name, table, column_name = index
print "CREATE INDEX %s ON %s (%s);" % (key_name, table, column_name)
$ ./drop_indexes.py
DROP INDEX idx_username ON users;
DROP INDEX idx_rights ON rights;
CREATE INDEX idx_username ON users (username);
CREATE INDEX idx_perm ON rights (perm);
Some important notes about the above script:
-
The script is not foolproof! If you have non-BTREE indexes, if you have indexes spanning multiple columns, if you have any kind of index that goes beyond a BTREE single column index, please be careful about using this script.
-
You must manually copy-paste the statements into the MySQL client.
-
It does NOT drop the PRIMARY KEY indexes.
Conclusions
In the end, I went from about 30 rows per second around 8000 rows per second. The key to getting decent performance is too start simple, and slowly expand your script while keeping a close eye on performance. If you see a dip, investigate immediately to mitigate the problem.
Useful ways of investigation slow performance is by using tools to unearth evidence of the root of the problem.
-
top can tell you if a process is mostly CPU bound. If you’re seeing high amounts of CPU, check if your queries are using indexes to get the results they need.
-
iostat can tell you if a process is mostly IO bound. If you’re seeing high amounts of I/O on your disk, tune MySQL to make better use of memory to buffer indexes and table data.
-
Use the EXPLAIN function of MySQL to see if, and which, indexes are being used. If not, create new indexes.
-
Avoid doing useless work such as updating indexes after every update. This is mostly a matter of knowing what to avoid and what not, but that’s what this post was about in the first place.
-
Baby steps! It took me entirely too long to figure out that I was initially seeing bad performance because my SELECT LIMIT n,m was being so slow. I was completely convinced my UPDATE statements were the cause of the initial slowdowns I saw. Only when I started commenting out the major parts of the code did I see that it was actually the simple SELECT query that was causing problems initially.
That’s it! I hope this was helpful in some way!
The text of all posts on this blog, unless specificly mentioned otherwise, are licensed under this license.
