Monday, March 14th, 2016
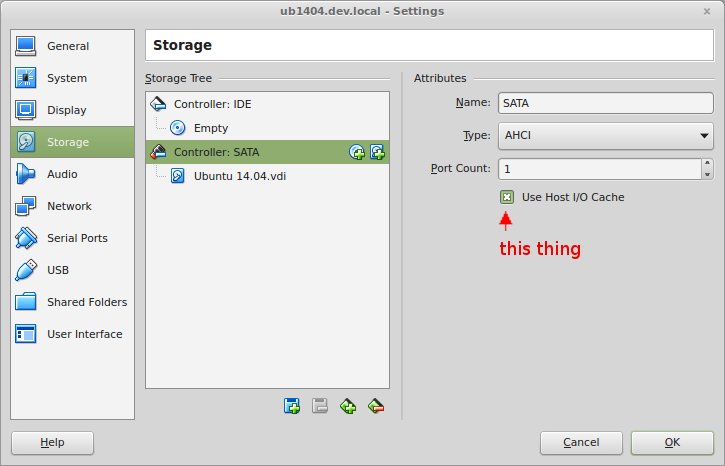
For a while I’ve noticed that Virtualbox has terrible performance when install Debian / Ubuntu packages. A little top, iotop and atop research later, and it turns out the culprit is the disk I/O, which is just ludicrously slow. The cause is the fact that Virtualbox doesn’t have “Use host IO cache” turned on by default for SATA controllers.Turning that option on gives a massive improvement to speed.
To turn “Host IO cache” on:
- Open the Virtual Machine’s Settings dialog
- Go to “Storage”
- Click on the “Controller: SATA” controller
- Enable the “Host I/O Cache” setting.
- You may also want to check any other controllers and / or disks to see if this option is on there.
- Save the settings and start the VM and you’ll see a big improvement.
Update:
Craig Gill was kind enough to mail me with the reasoning behind why the “Host I/O cache” setting is off by default:
Hello, thanks for the blog post, I just wanted to comment on it below:
In your blog post “Terrible Virtualbox disk performance”, you mention
that the ‘use host i/o cache’ is off by default.
In the VirtualBox help it explains why it is off by default, and it
basically boils down to safety over performance.
Here are the disadvantages of having that setting on (which these
points may not apply to you):
1. Delayed writing through the host OS cache is less secure. When the
guest OS writes data, it considers the data written even though it has
not yet arrived on a physical disk. If for some reason the write does
not happen (power failure, host crash), the likelihood of data loss
increases.
2. Disk image files tend to be very large. Caching them can therefore
quickly use up the entire host OS cache. Depending on the efficiency
of the host OS caching, this may slow down the host immensely,
especially if several VMs run at the same time. For example, on Linux
hosts, host caching may result in Linux delaying all writes until the
host cache is nearly full and then writing out all these changes at
once, possibly stalling VM execution for minutes. This can result in
I/O errors in the guest as I/O requests time out there.
3. Physical memory is often wasted as guest operating systems
typically have their own I/O caches, which may result in the data
being cached twice (in both the guest and the host caches) for little
effect.
“If you decide to disable host I/O caching for the above reasons,
VirtualBox uses its own small cache to buffer writes, but no read
caching since this is typically already performed by the guest OS. In
addition, VirtualBox fully supports asynchronous I/O for its virtual
SATA, SCSI and SAS controllers through multiple I/O threads.”
Thanks,
Craig
That’s important information to keep in mind. Thanks Craig!
My reply:
Thanks for the heads up!
For what it’s worth, I already wanted to write the article a few weeks ago, and have been running with all my VirtualBox hosts with Host I/O cache set to “on”, and I haven’t noticed any problems. I haven’t lost any data in databases running on Virtualbox (even though they’ve crashed a few times; or actually I killed them with ctrl-alt-backspace), the host is actually more responsive if VirtualBoxes are under heavy disk load. I do have 16 Gb of memory, which may make the difference.
The speedups in the guests is more than worth any other drawbacks though. The gitlab omnibus package now installs in 4 minutes rather than 5+ hours (yes, hours).
I’ll keep this blog post updates in case I run into any weird problems.
Update: I’ve been running with Host I/O caching on for almost 6 months now. I’ve noticed no performance degradations on the host or other Virtual Machines. I regularly (about 3 times a week) have to hard power-cycle my laptop due to a kernel bug for my Wifi driver. I’ve noticed no data loss in my VMs. Then again, I don’t use them for mission critical applications, nor do they do a lot of write disk I/O. The performance increase on disk I/O in the VM remains extremely high.
Friday, March 4th, 2016
There are many Markdown previewers out there, from the simplest commandline tool + webbrowser to full-fledged Markdown IDE’s. I’ve tried quite a few, and I like none of them. I write my Markdown in an external editor (Vim), something very few Markdown previewers take in account. The ones that do are buggy. So I wrote mdpreview, a standalone Markdown previewer for Linux that works great with an external editor such as Vim. The main selling points:
- Automatic reload when your Markdown file changes. Unlike many other previewers, it remembers your scroll position during reload and doesn’t put you back at the top.
- Themes that closely resemble Github and Bitbucket, so you actually know what it’s going to look like when published. There are also some additional themes that are nice on the eyes (solarized).
- An option to set Keep-on-top window hinting, so the previewer always stays on top of other windows.
- Vi motion keys (
j, k, G, g)
- Append detection. If the end of the document is being viewed and new contents is appended, mdpreview automatically scrolls to the bottom.
- mdpreview remembers your window size and position. A very basic feature you’d think most previewers would support, but don’t.
A feature to automatically scroll to the last made change in the Markdown file is currently being implemented.
Here’s mdpreview running the Solarized theme:
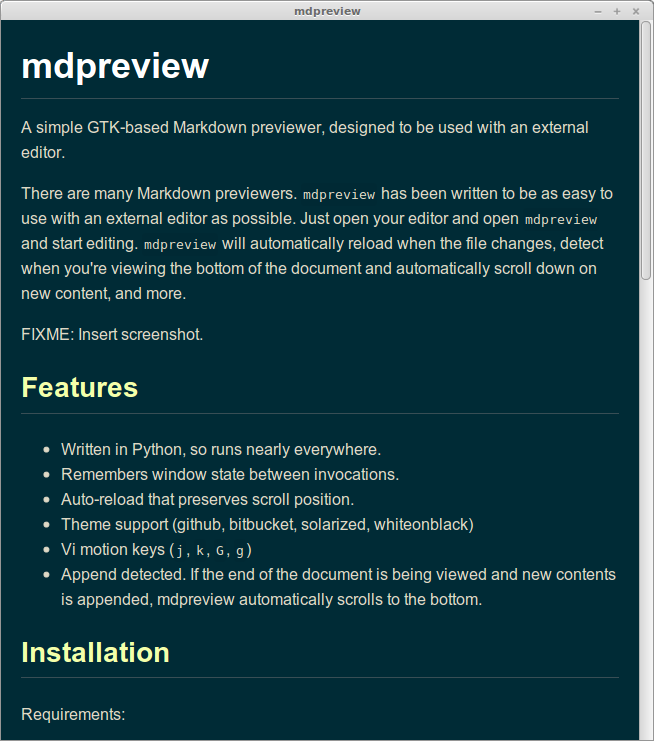
The Github theme:
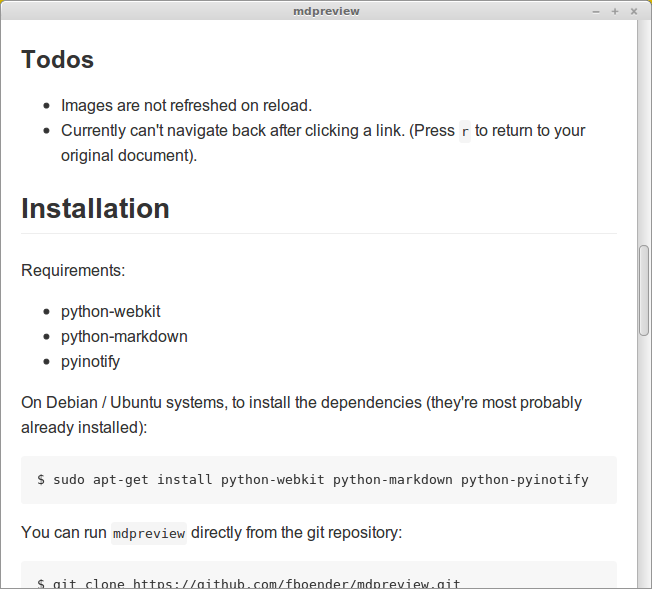
And the BitBucket theme:
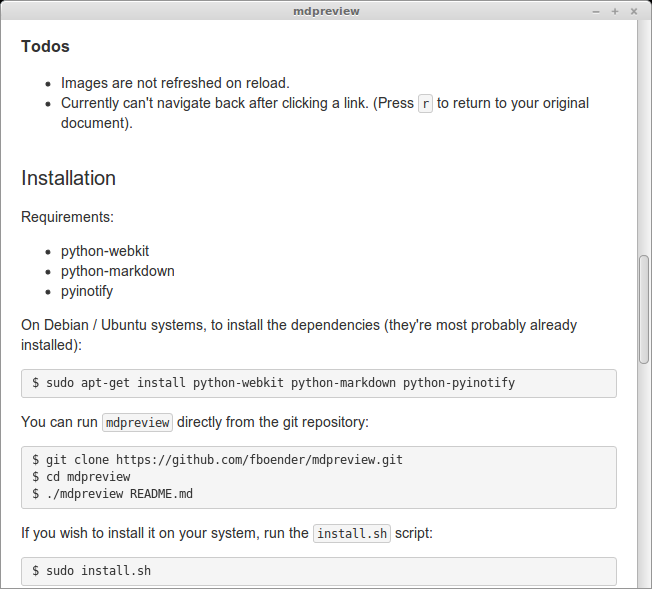
More information and installation instructions are available on the Github page.
Wednesday, March 2nd, 2016
I was trying to manually scroll a (Python) GTK embedded Webview in order to position the webview back to where it was after setting new contents with webview.load_html_string(html, 'file:///'). I couldn’t get it to work, and Google wasn’t of much help either.
I could scroll the Webview just fine from a key-press-event handler on the main window like this:
def __init__(self):
# -- Removed some code here for brevity --
self.scroll_window = gtk.ScrolledWindow(None, None)
self.scroll_window.add(self.webview)
self.win_main.connect("key-press-event", self.ev_key_press_event)
def ev_key_press_event(self, widget, ev):
if ev.keyval == gtk.keysyms.t:
self.scroll_window.get_vadjustment().set_value(100)
But automatically scrolling when something happened to the webview (in my case new content being set via webview.load_html_string()) didn’t work.
It turns out that the webview is still handling events and won’t allow scrolling using `scroll_window.get_vadjustment().set_value()` until all the events are handled.
You can manually handle all the pending GTK events before starting scrolling like this:
def __init__(self):
# -- Removed some code here for brevity --
self.scroll_window = gtk.ScrolledWindow(None, None)
self.scroll_window.add(self.webview)
webview.connect('notify::load-status', self.ev_load_status)
def ev_load_status(self, webview, load_status):
if self.webview.get_load_status() == webkit.LOAD_FINISHED:
while gtk.events_pending():
gtk.main_iteration_do()
self.scroll_window.get_vadjustment().set_value(100)
The solution above works for me on both initial load of a document and subsequent changing of the webkit contents using `webview.load_html_string()`.
Monday, February 15th, 2016
 I’m writing a simple web application in the Bottle framework. I ran into an issue where I had a single long-running request, but needed to make some additional requests from the browser to the server. It turns out that Bottle’s built in development web server is single-threaded, and can’t handle multiple requests at the same time. This is annoying, since I don’t want to have to deploy my application each time I make a change; that’s what’s the built-in development web server is for.
I’m writing a simple web application in the Bottle framework. I ran into an issue where I had a single long-running request, but needed to make some additional requests from the browser to the server. It turns out that Bottle’s built in development web server is single-threaded, and can’t handle multiple requests at the same time. This is annoying, since I don’t want to have to deploy my application each time I make a change; that’s what’s the built-in development web server is for.
The solution is easy: create a very simple multithreaded WSGI web server and use that to serve the Bottle application.
wsgiserver.py
"""
Simple multithreaded WSGI HTTP server.
"""
from wsgiref.simple_server import make_server, WSGIServer
from SocketServer import ThreadingMixIn
class ThreadingWSGIServer(ThreadingMixIn, WSGIServer):
daemon_threads = True
class Server:
def __init__(self, wsgi_app, listen='127.0.0.1', port=8080):
self.wsgi_app = wsgi_app
self.listen = listen
self.port = port
self.server = make_server(self.listen, self.port, self.wsgi_app,
ThreadingWSGIServer)
def serve_forever(self):
self.server.serve_forever()
We then include that in the file where we create our Bottle app:
app.py
import bottle
import wsgiserver
wsgiapp = bottle.default_app()
httpd = wsgiserver.Server(wsgiapp)
httpd.serve_forever()
We now have a Bottle app that can handle multiple concucrrent requests. I’m not sure how well this works with automatic reloading and such, but I think it should be fine.
Monday, February 15th, 2016
I’ve just released ansible-cmdb v1.12. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates and extending information gathered by Ansible with custom data.
This release includes the following bugfixes and feature improvements:
- Bugfix: Don’t parse hidden files in fact output dirs.
- Bugfix: Various fixes in html_fancy template that prevent output from being generated if certain facts are missing.
- Bugfix: Improved error handling to prevent ansible-cmdb from stopping on a single invalid host.
- Improved error reporting
- Ansible local facts (from /etc/ansible/facts.d on hosts) is now shown in the Host details overview.
- Support undocumented extended YAML vars in hosts files.
- txt_table: Show MemFree and MemUsed columns. (by Kurt Davis)
- txt_table: Properly align table columns if the values are less wide than the title.
As always, packages are available for Debian, Ubuntu, Redhat, Centos and other systems. Get the new release from the Github releases page.
Wednesday, January 20th, 2016
Recently I suddently couldn’t log into Openvas v8 running on Ubuntu 14.04 anymore. Nothing had changed about the machine (as far as I knew), but I got the following message when trying to log in with any account:
Login failed. OMP service is down
The logs (/var/log/openvas/openvasmd.log) showed the following message:
lib serv:WARNING:2016-01-19 15h52.12 utc:21760: Failed to shake hands with peer: The signature algorithm is not supported.
lib serv:WARNING:2016-01-19 15h52.22 utc:21775: Failed to shake hands with peer: A TLS packet with unexpected length was received.
md main:CRITICAL:2016-01-19 15h52.22 utc:21775: serve_client: failed to attach client session to socket 12
lib serv:WARNING:2016-01-19 15h52.22 utc:21775: Failed to gnutls_bye: GnuTLS internal error.
lib auth: INFO:2016-01-19 15h53.56 utc:25472: Authentication configuration not found.
Turns out the libgnutls library was updated and it turned off support for downgrading signature algorithms.
If you got your Openvas installation from the Mrazavi Launchpad source, you can fix the problem by simply updating and upgrading:
sudo apt-get update && sudo apt-get upgrade
Tuesday, January 12th, 2016
I’ve just released ansible-cmdb v1.11. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates and extending information gathered by Ansible with custom data.
This release includes the following bugfixes and feature improvements:
- Source package improvements in man page handling (Alex Barton)
- html_fancy template now supports OpenBSD facts.
- html_fancy template now supports Windows (2008) facts.
- html_fancy template now shows a link icon instead of a star for the search box URL.
- Improved error reporting and debugging mode (-d).
Get the new release from the Github releases page.
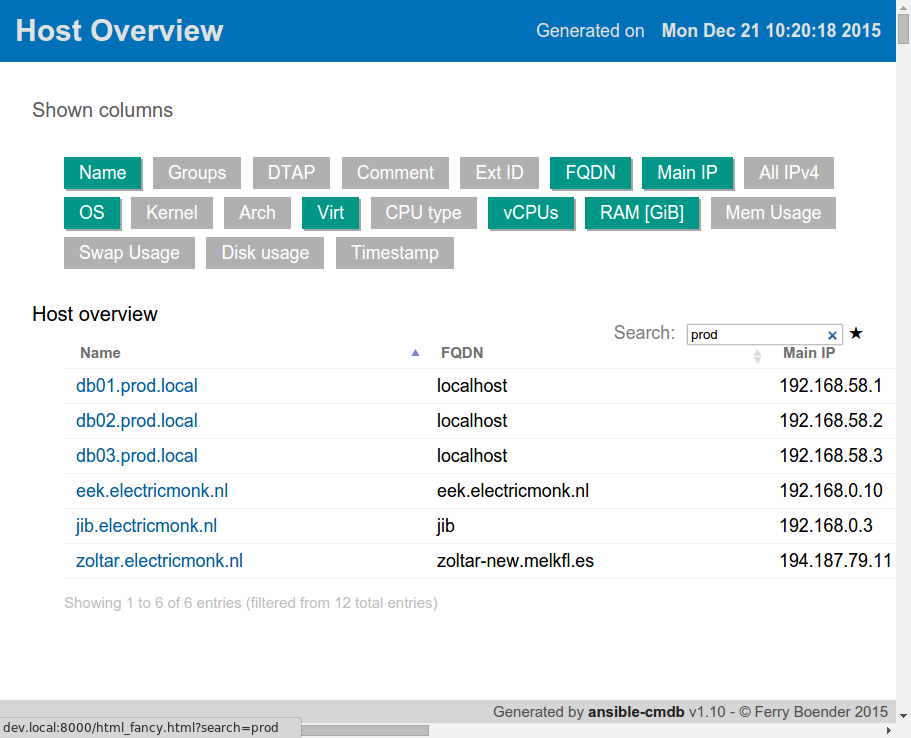
Monday, December 21st, 2015
I’ve just released ansible-cmdb v1.10. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates and extending information gathered by Ansible with custom data.
This is a feature and bugfix release, including the following changes:
- Fix for UTF-8 characters appearing in hosts and fact files.
- The searchbox now shows a star next to it, which can be used to link directly to the search results.
- The host headers are now links, so you can easily link to them
Screenshot:
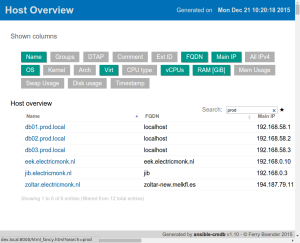
Get the new release from the Github releases page.
Monday, December 7th, 2015
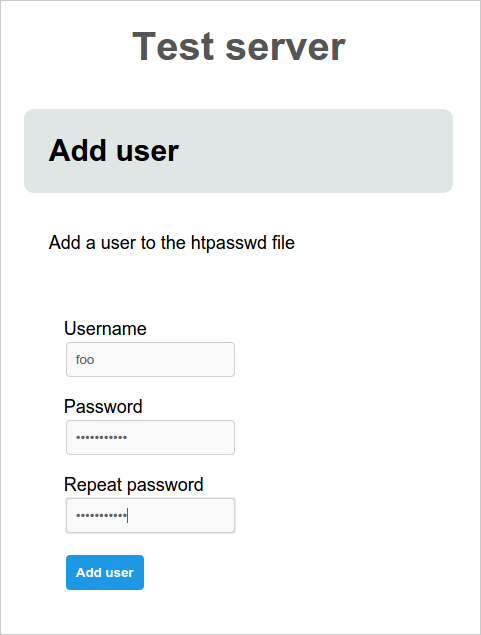 I’ve just releases v1.0 of ScriptForm.
I’ve just releases v1.0 of ScriptForm.
ScriptForm is a stand-alone webserver that automatically generates forms from JSON to serve as frontends to scripts. It takes a JSON file which contains form definitions, constructs web forms from this JSON and serves these to users over HTTP. The user can select a form and fill it out. When the user submits the form, it is validated and the associated script is called. Data entered in the form is passed to the script through the environment. See the Example to learn more about how it works.
I wrote ScriptForm to quickly give non-technical users the ability to perform restricted actions through a friendly web interface. Some use-cases I’ve used it for so far:
- Allow users to upload CSV files that need to be processed
- Let non-technical users create and modify Apache htpasswd files (add, delete and reset user passwords).
- Give customers the ability to view their services’ status and restart certain services which tend to hang every so often.
- Given a certain date range, export data as CSV files.
- Serve as a simple REST API that’s incredibly easy to set up and use.
Some features it includes are:
- Very rapidly construct forms with backends.
- Completely standalone HTTP server; only requires Python.
- Callbacks to any kind of script / program that supports environment variables.
- User authentication support through Basic HTAuth.
- Validates form values before calling scripts.
- Uploaded files are automatically saved to temporary files, which are passed on to the callback.
- Multiple forms in a single JSON definition file.
- Scripts can produce normal output, HTML output or stream their own HTTP response to the client. The last one lets you stream images or binaries to the browser.
- Run scripts as different users without requiring sudo.
ScriptForm is Free Software / Open Source software released under the GNU GPL v3.
Some links for further information:
Github repository / source: https://github.com/fboender/scriptform
Download releases: https://github.com/fboender/scriptform/releases, packages are available for Debian, Redhat and other Linux-bases systems.
Screenshots: https://github.com/fboender/scriptform/tree/master/doc/screenshots
Tutorial: https://github.com/fboender/scriptform/blob/master/doc/MANUAL.md#tutorial
Manual: https://github.com/fboender/scriptform/blob/master/doc/MANUAL.md
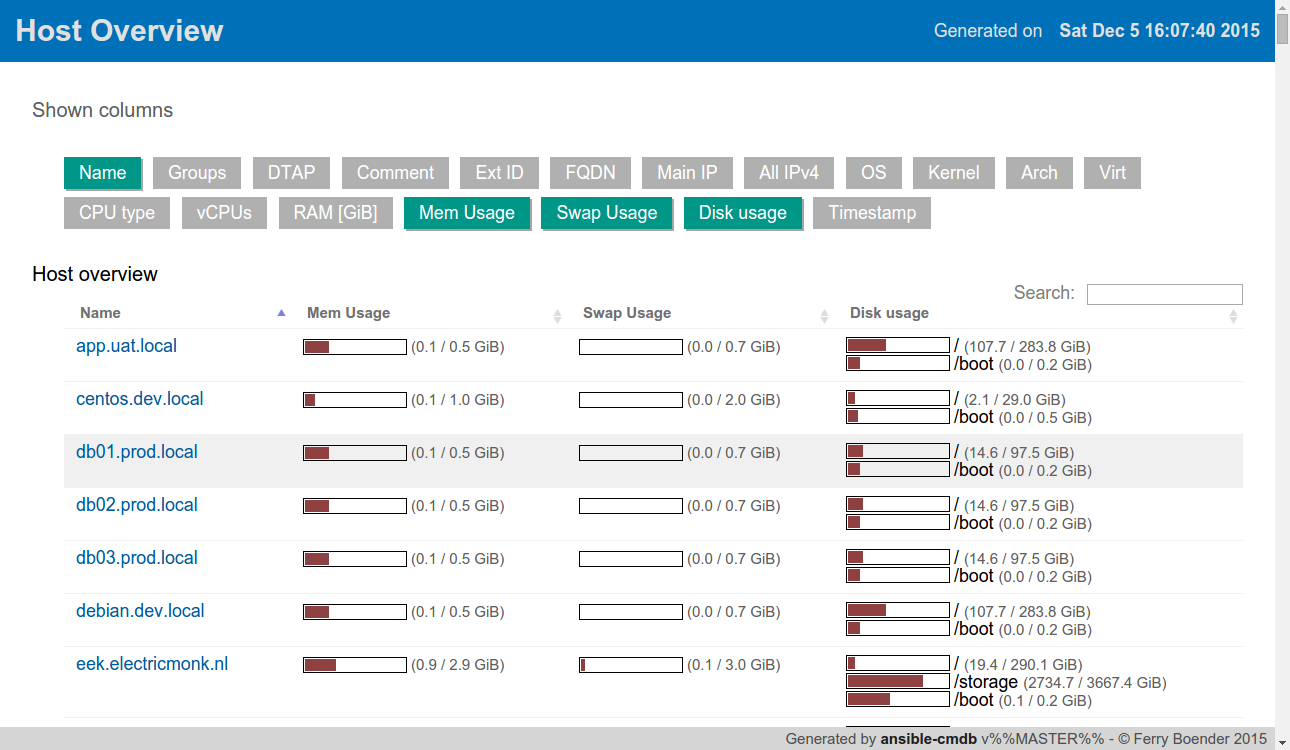
Saturday, December 5th, 2015
I’ve just released ansible-cmdb v1.9. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates and extending information gathered by Ansible with custom data.
This is a feature and bugfix release, including the following changes:
- Always output UTF-8.
- Added the ‘json’ template, which dumps the entire inventory including variables and groups in JSON format.
- Included a manual page in the packages.
- The -t/–template switch can now point to an actual filename, and no longer requires the .tpl extension to be stripped.
- html_fancy: Fixed a bug where the search field was not properly focussed.
- html_fancy: Use vcpus for cores + hyperthreading count (Rowin Andruscavage)
- html_fancy: New cpu, memory, swap columns and improved sorting (Rowin Andruscavage)
- html_fancy: Show a hosts groups in the detailed view
- html_fancy: Move and disable/enable some default columns.
- html_fancy: Network overview table for host details.
Here’s a screenshot showing some of the new columns:
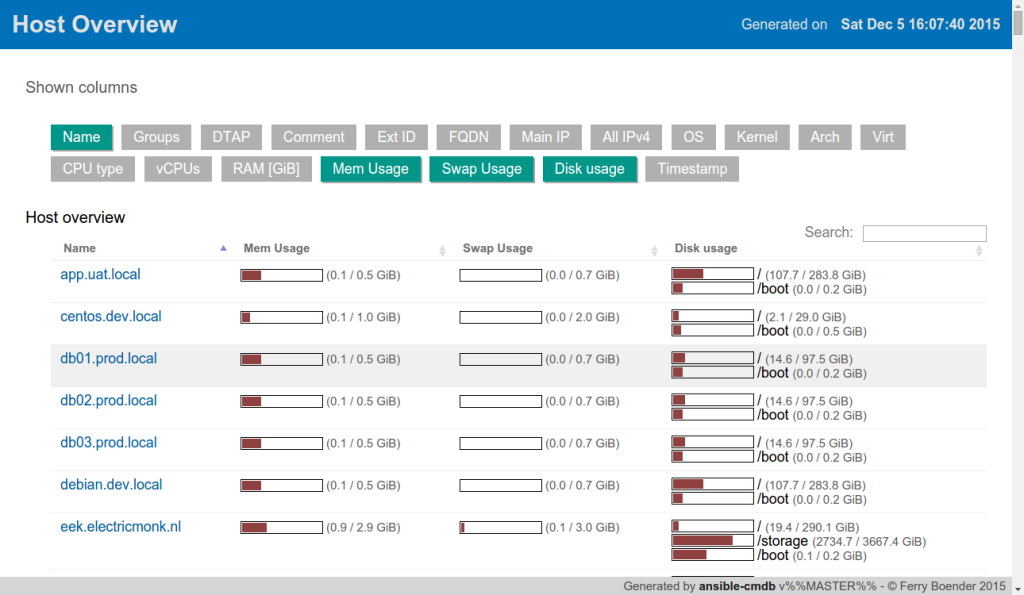
Get the new release from the Github releases page.
The text of all posts on this blog, unless specificly mentioned otherwise, are licensed under this license.