Saturday, July 8th, 2017
Another case of online theft whereby the attacker takes over a victim’s phone and performs an account reset through SMS has just hit the web. This is the sixth case I’ve read about, but undoubtedly there are many many more. In this case, the victim only lost $200. In other cases, victims have lost thousands of dollars worth of bitcoins in a very similar method of attack.
Basically every site in existence, including banks, paypal and bitcoin wallets offer password resets via email. This makes your email account an extremely important weak link in the chain of your security. If an attacker manages to get into your email account, you’re basically done for. But you’re using Gmail, and their security is state-of-the-art, right? Well, no.. read on.
So how does the attack work? It’s really simple. An attacker doesn’t need to break any military-grade crypto or perform magic man-in-the-middle DNS cache poisoning voodoo. All they have to do is:
- Call your cellphone provider.
- Get them to forward your phone number to a different phone (of which there are several possibilities)
- Request a password reset on your mail account.
- Receive the recovery code via SMS
- Reset the password on your mail account with the recovery code
- Reset any other account you own through your email box.
That’s all it takes. Even the most unsophisticated attacker can pull this off and get unrestricted access to every account you own!
The weakness lies in step 2: getting control over your phone number. While you may think this is difficult, it really isn’t. Telco’s, like nearly all big companies, are horrible at security. They’ll get security audits up the wazoo every few months, but the auditors themselves are usually way behind the curve when it comes to the latest attack vectors. Most security auditors still insist on nonsense such as a minimum of 8 character (16 is more like it) passwords and changing them every few months. Because, you know, the advice of not using the same password for different services is way beyond them.
In the story linked above, the Human element, like always, is the problem:
The man on the phone reads through the notes and explains that yes, someone has been dialing the AT&T call center all day trying to get into my phone but was repeatedly rejected because they didn’t know my passcode, until someone broke protocol and didn’t require the passcode.
Someone broke protocol. Naturally that is only possible if employees of AT&T have unrestricted privileges to override the passcode requirement and modify anybody’s data. Exactly the sort of thing that receives no scrutiny in a security audit. They’ll require background checks on employees to see if they’re trustworthy, while competely neglecting the fact that it’s much mure likely that trustworthy employees merely make mistakes.
A few weeks ago I was the “victim” of a similar incident. I suddenly started receiving emails from a big Dutch online shop regarding my account there. The email address of my account had been changed and my password had been reset. I immediately called the helpdesk and within a few minutes the helpdesk employee had put everything straight. It turns out that someone in the Netherlands with the exact same name as me (which is very uncommon) had mistaken my account for his and had requested his email address be reset through some social media support method. Again, no restrictions or verifications that he was the owner of the account were required. If it hadn’t been for their warning emails, the promptness of the helpdesk employee and the fact that my “attacker” meant no harm, I could have easily been in trouble.
The lessons here are clear:
- Users: don’t use your phone number as a recovery device. It may seem safe, but it’s not. Even Google / Gmail don’t just allow you to do this, they actively encourage this bad security practice. Delete your phone number as a recovery device and use downloadable backup codes.
- Users: don’t use two-factor authentication through SMS. It’s better to not use two-factor authentication at all if SMS is the only option. Without two-factor authentication, they have to guess your password. With two-factor authentication through SMS, they only have to place a call or two to your provider. And your provider will do as they ask, make no mistake about it.
- Companies: stop offering authentication, verification and account recovery through phone numbers! Use TOTP (RFC 6238) for two-factor authentication and offer backup codes or a secret key (no, that does not mean those idiotic security questions asking for my mothers maiden name) or something.
- Companies: Do NOT allow employees to override such basic security measures as Account Owner Verification! This really should go without saying, but it seems big companies are just too clueless to get this right. A person has to be able to prove they’re the owner of the account! And for Pete’s sake, please stop using easily obtained info such as my birth date and address as verification! If you really must have a way of overriding such things, it should only be possible for a single senior account manager with a good grasp of security.
As more and more aspects of our lives are managed online, the potential for damage to our real lives keeps getting bigger. Government institutes and companies are scrambling to go online with their services. It’s more cost efficient and convenient for the customer. But the security is severely lacking.
The online world is not like the real world, where it takes a large amount of risky work for an attacker to obtain a small reward. On the internet, anyone with malicious intent and the most basic level of literacy can figure out how to reap big rewards at nearly zero risk. As we’ve seen with the recent Ransomwares and other attacks, those people are out there and are actively abusing our bad security practices. If you, the reader, had any idea how horrible the security of everything in our daily lives is, from your online accounts to the lock on your cars, you’d be highly surprised that digital crime wasn’t much, much more widespread.
Let’s pull our head out of our asses and give online security the priority it deserves.
Sunday, May 7th, 2017
Say we have two Python dictionaries:
{
'name': 'Ferry',
'hobbies': ['programming', 'sci-fi']
}
and
{
'hobbies': ['gaming']
}
What if we want to merge these two dictionaries such that “gaming” is added to the “hobbies” key of the first dictionary? I couldn’t find anything online that did this already, so I wrote the following function for it:
# Copyright Ferry Boender, released under the MIT license.
def deepupdate(target, src):
"""Deep update target dict with src
For each k,v in src: if k doesn't exist in target, it is deep copied from
src to target. Otherwise, if v is a list, target[k] is extended with
src[k]. If v is a set, target[k] is updated with v, If v is a dict,
recursively deep-update it.
Examples:
>>> t = {'name': 'Ferry', 'hobbies': ['programming', 'sci-fi']}
>>> deepupdate(t, {'hobbies': ['gaming']})
>>> print t
{'name': 'Ferry', 'hobbies': ['programming', 'sci-fi', 'gaming']}
"""
for k, v in src.items():
if type(v) == list:
if not k in target:
target[k] = copy.deepcopy(v)
else:
target[k].extend(v)
elif type(v) == dict:
if not k in target:
target[k] = copy.deepcopy(v)
else:
deepupdate(target[k], v)
elif type(v) == set:
if not k in target:
target[k] = v.copy()
else:
target[k].update(v.copy())
else:
target[k] = copy.copy(v)
It uses a combination of deepcopy(), updating and self recursion to perform a complete merger of the two dictionaries.
As mentioned in the comment, the above function is released under the MIT license, so feel free to use it any of your programs.
Monday, May 1st, 2017
I’ve just released v1.3 of Scriptform.
ScriptForm is a stand-alone webserver that automatically generates forms from JSON to serve as frontends to scripts. It takes a JSON file which contains form definitions, constructs web forms from this JSON and serves these to users over HTTP. The user can select a form and fill it out. When the user submits the form, it is validated and the associated script is called. Data entered in the form is passed to the script through the environment.
You can get the new release from the Releases page.
More information, including screenshots, can be found on the Github page.
Wednesday, March 1st, 2017
Getting HTTP error 429 when trying to call Reddit APIs or .json endpoints? Try changing your User Agent header to something else. Reddit bans based on user agent.
Thursday, February 23rd, 2017
I generate release packages for my software with Alien, which amongst other things converts .deb packages to .rpm.
On Fedora 24 however, the generated RPMs cause a small problem when installed with Yum:
Transaction check error:
file / from install of cfgtrack-1.0-2.noarch conflicts with file from package filesystem-3.2-20.el7.x86_64
file /usr/bin from install of cfgtrack-1.0-2.noarch conflicts with file from package filesystem-3.2-20.el7.x86_64
There’s a bit of info to be found on the internet about this problem, with most of the posts suggesting using rpmrebuild to fix it. Unfortunately, it looks like rpmrebuild actually requires the package to be installed, and since I don’t actually use a RPM-based system, that was a bit of a no-go.
So here’s how to fix those packages manually:
First, use Alient to generate a RPM package folder from a Debian package, but don’t generate the actual package yet. You can do so with the -g switch:
alien -r -g -v myproject-1.0.deb
This generates a myproject-1.0 directory containing the root fs for the package as well as a myproject-1.0-2.spec file. This spec file is the actual problem. It defines directories for paths such as / and /usr/bin. But those are already provided by the filesystem package, so we shouldn’t include them.
You can remove them from a script using sed:
sed -i 's#%dir "/"##' myproject-1.0/myproject-1.0-2.spec
sed -i 's#%dir "/usr/bin/"##' myproject-1.0/myproject-1.0-2.spec
This edits the spec file in-place and replaces the following lines with empty lines:
%dir "/"
%dir "/usr/bin/"
The regular expressions look somewhat different than usual, because I’m using the pound (#) sign as a reg marker instead of “/”.
Finally, we can recreate the package using rpmbuild:
cd myproject-1.0
rpmbuild --target=noarch --buildroot /full/path/to/myproject-1.0/ \
-bb cfgtrack-$(REL_VERSION)-2.spec
The resulting package should install without errors or warnings now.
Monday, February 20th, 2017
I was looking for a message queue that could reliably handle messages in such a way that I was guaranteed never to miss one, even if the consumer is offline or crashes. Mosquitto (MQTT) comes very close to that goal. However, it wasn’t directly obvious how to configure it to be as reliable as possible So this post describes how to use Mosquitto to ensure the most reliable delivery it can handle.
TL;DR: You can’t
If you want to do reliable message handling with Mosquitto, the short answer is: You can’t. For the long answer, read the rest of the article. Or if you’re lazy and stubborn, read the “Limitations” section further down. ;-)
Anyway, let’s get on with the show and see how close Mosquitto can get.
Quick overview of Mosquitto
Here’s a quick schematic of Mosquitto components:
+----------+ +--------+ +----------+
| producer |---->| broker |---->| consumer |
+----------+ +--------+ +----------+
The producer sends messages to a topic on the broker. The broker maintains an internal state of topics and which consumers are interested in which topics. It also maintains a queue of messages which still need to be sent to each consumer. How the broker decided what / when to send to which consumer depends on settings such as the QoS (Quality of Service) and what kind of session the consumer is opening.
Producer and consumer settings
Here’s a quick overview of settings that ensure the highest available quality of delivery of messages with Mosquitto. When creating a consumer or producer, ensure you set these settings properly:
- quality-of-service must be
2.
- The consumer must send a client_id.
- clean_session on the consumer must be
False.
These are the base requirements to ensure that each consumer will receive messages exactly once, even if they’ve been offline for a while. The quality-of-service setting of 2 ensures that the broker requires acknowledgement from the consumer that a message has been received properly. Only then does the broker update its internal state to advance the consumer to the next message in the queue. If the client crashes before acknowledging the message, it’ll be resent the next time.
The client_id gives the broker a unique name under which to store session state information such as the last message the consumer has properly acknowledged. Without a client_id, the broker cannot do this.
The clean_session setting lets the consumer inform the broker about whether it wants its session state remembered. Without it, the broker assumes the broker assumes the consumer does not care about past messages and such. It will only receive any new messages that are produced after the consumer has connected to the broker.
Together these settings ensure that messages are reliably delivered from the producer to the broker and to the consumer, even if the consumer has been disconnected for a while or crashes while receiving the message.
Broker settings
The following settings are relevant configuration options on the broker. You can generally find these settings in/etc/mosquitto/mosquitto.conf.
- The broker must have persistence set to
True in the broker configuration.
- You may want to set max_inflight_messages to 1 in the broker configuration to ensure correct ordering of messages.
- Configure max_queued_messsages to the maximum number of messages to retain in a queue.
- Tweak autosave_interval to how often you want the broker to write the in-memory database to disk.
The persistence setting informs the broker that you’d like session state and message queues written to disk. If the broker for some reason, the messages will (mostly) still be there.
You can ensure that messages are sent to consumers in the same order as they were sent to the broker by the producers by setting the max_inflight_messages setting to 1. This will probably severely limit the throughput speed of messages.
The max_queued_messsages determines how many unconfirmed messages should maximally be retained in queues. This should basically be the product of the maximum number of messages per second and the maximum time a consumer might be offline. Say we’re processing 1 message per second and we want the consumer to be able to be offline for 2 hours (= 7200 seconds), then the max_queued_messsages setting should be 1 * 7200 = 7200.
The autosave_interval determines how often you want the broker to write the in-memory database to disk. I suspect that setting this to a very low level will cause severe Disk I/O activity.
Examples
Here’s an example of a producer and consumer:
producer.py:
import paho.mqtt.client as paho
import time
client = paho.Client(protocol=paho.MQTTv31)
client.connect("localhost", 1883)
client.loop_start()
client.publish("mytesttopic", str("foo"), qos=2)
time.sleep(1) # Give the client loop time to proess the message
consumer.py:
import paho.mqtt.client as paho
def on_message(client, userdata, msg):
print(msg.topic+" "+str(msg.qos)+" "+str(msg.payload))
client = paho.Client("testclient", clean_session=False, protocol=paho.MQTTv31)
client.on_message = on_message
client.connect("localhost", 1883)
client.subscribe("mytesttopic", qos=2)
client.loop_forever()
Pitfalls
There are a few pitfalls I ran into when using Mosquitto:
- If the broker or one of the clients doesn’t support the
MQTTv32 protocol, things will fail silently. So I specify MQTTv31 manually.
- The
client loop needs some time to process the sending and receiving of messages. If you send a single message and exit your program right away, the loop doesn’t have time to actually send the message.
- The
subscriber must have already run once before the broker will start keeping messages for it. Otherwise, the broker has no idea that a consumer with QoS=2 is interested in messages (and would have to keep messages for ever). So register your consumer once by just running it, before the producer runs.
Limitations
Although the settings above make exchanging messages with Mosquitto more reliable, there are still some downsides:
- Exchanging messages in this way is obviously slower than having no consistency checks in place.
- Since the Mosquitto broker only writes the in-memory database to disk every X (where X is configurable) seconds, you may lose data if the broker crashes.
- On the consumer side, it is the MQTT library that confirms the receipt of the message. However, as far as I can tell, there is no way to manually confirm the receipt of a message. So if your client crashes while handling a message, rather than while it is receiving a message, you may still lose the message. If you wish to handle this case, you can store the message on the client as soon as possible. This is, however, not much more reliable. The only other way is to implement some manual protocol via the exchange of messages where the original publisher retains a message and resends it unless its been acknowledged by the consumer.
Conclusion
In other words, as far as I can see, you cannot do reliable message handling with Mosquitto. If your broker crashes or your client crashes, Mosquitto will lose your messages. Other than that, if all you require is reliable delivery of messages to the client, you’re good to go.
So what are the alternatives? At this point, I have to honest and say: I don’t know yet. I’m personally looking for a lightweight solution, and it seems none of the lightweight Message Queues do reliable message handling (as opposed to reliable messagedelivery, which most do just fine).
When I find an answer, I’ll let you know here.
Monday, February 13th, 2017
I’ve just released ansible-cmdb v1.20. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates (fancy html, txt, markdown, json and sql) and extending information gathered by Ansible with custom data.
This release includes the following changes:
- Support for installation in a VirtualEnv.
- New columns in the html_fancy template for the number of network interfaces and physical disk sizes.
- Improved error reporting.
- Added a “Reset settings” button to the html_fancy template that resets localStorage
- The user that generated the overview and the host it was generated on are now shown in the html_fancy output.
- Various minor cosmetic changes to the html_fancy template.
- Work properly with disk sizes of 0 bytes.
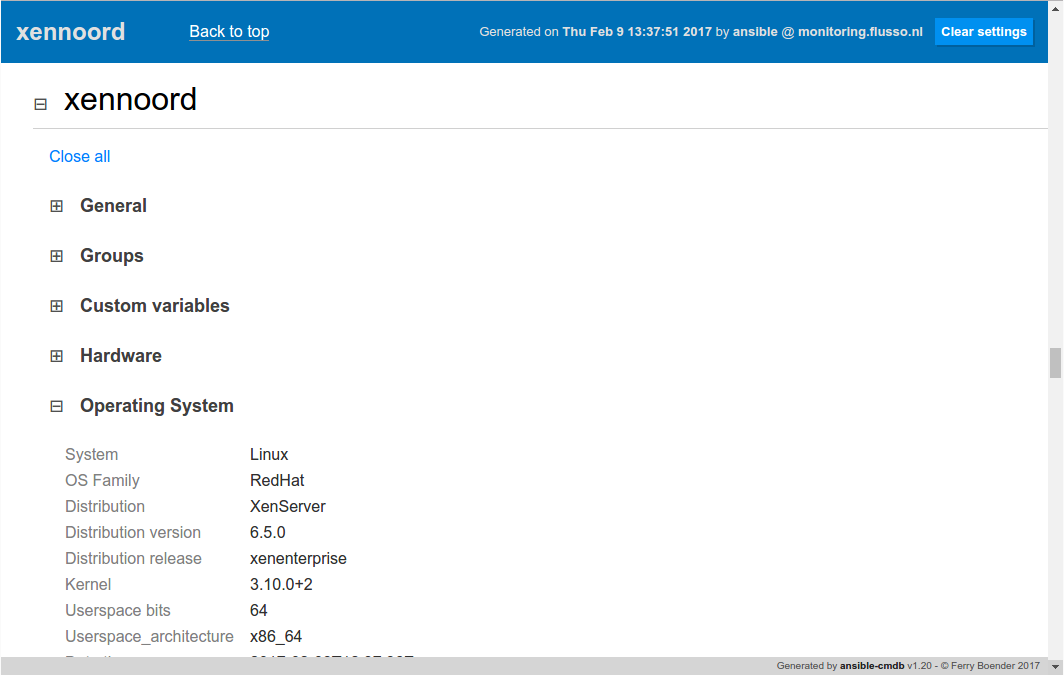
- Host detail information in the html_fancy template can now be collapsed. Use the -p collapse=1 flag to automatically collapse all sections..
As always, packages are available for Debian, Ubuntu, Redhat, Centos and other systems. Get the new release from the Github releases page.
Here’s a screenshot of the collapsing host details:
Monday, February 6th, 2017
ScriptForm is a stand-alone webserver that automatically generates forms from JSON to serve as frontends to scripts. It takes a JSON file which contains form definitions, constructs web forms from this JSON and serves these to users over HTTP. The user can select a form and fill it out. When the user submits the form, it is validated and the associated script is called. Data entered in the form is passed to the script through the environment.
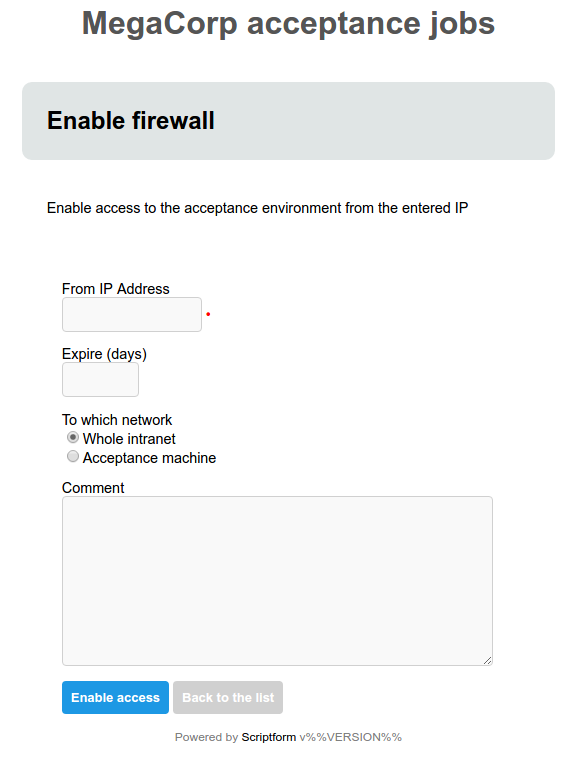
Some links for further information:
Github repository / source: https://github.com/fboender/scriptform
Download releases: https://github.com/fboender/scriptform/releases, packages are available for Debian, Redhat and other Linux-bases systems.
Screenshots: https://github.com/fboender/scriptform/tree/master/doc/screenshots
Tutorial: https://github.com/fboender/scriptform/blob/master/doc/MANUAL.md#tutorial
Manual: https://github.com/fboender/scriptform/blob/master/doc/MANUAL.md
This release (v1.1) features the following changes:
- Improved form configuration loading error messages.
- Passwords containing a ‘:’ caused problems.
- When incorrect redirects were done, or if the user specified an URL starting with two slashes, Scriptform would show a 500 error.
- When stopping or restarting Scriptform, a harmless error about missing arguments to _cleanup() would be shown in the log file.
- Various updates to the documentation and examples.
Monday, January 9th, 2017
I’ve just released ansible-cmdb v1.19. Ansible-cmdb takes the output of Ansible’s fact gathering and converts it into a static HTML overview page containing system configuration information. It supports multiple templates (fancy html, txt, markdown, json and sql) and extending information gathered by Ansible with custom data.
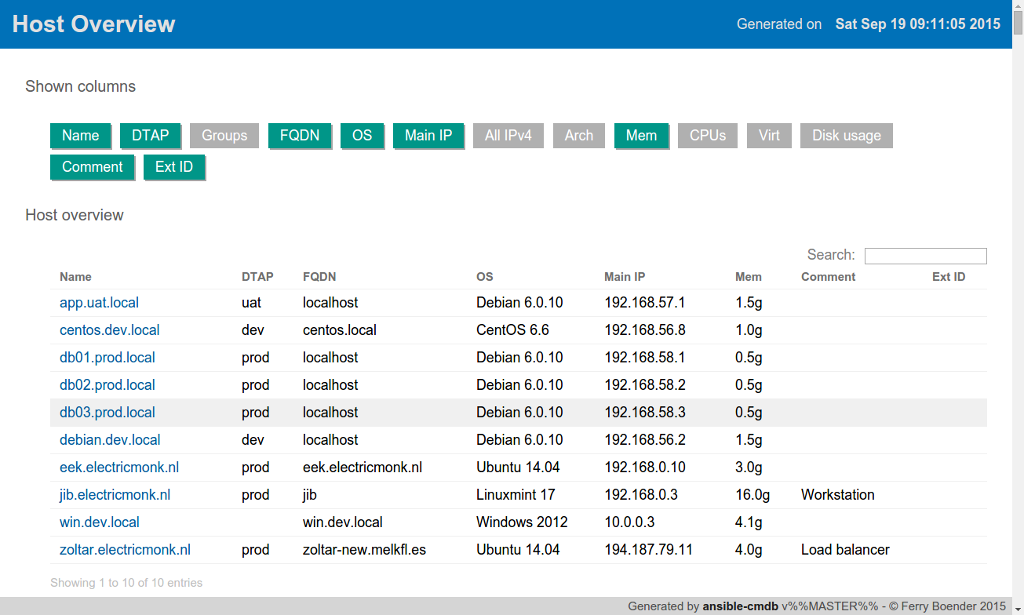
This release includes the following bugfixes;:
- Always show stack trace on error and include class name.
- Exit with proper exit codes.
- Exclude certain file extensions from consideration as inventories.
- Improved error reporting and lookups of templates.
- Improved error reporting when specifying inventories.
As always, packages are available for Debian, Ubuntu, Redhat, Centos and other systems. Get the new release from the Github releases page.
Monday, January 9th, 2017
After almost a year of no releases, I’ve made a new release of Bexec today. It’s a minor feature release that brings a new setting to Bexec: bexec_splitsize. This settings controls the default size of the output window. You can set it in your .vimrc as follows:
let g:bexec_splitsize=20
This will always make the output window 20 lines high.
It’s been almost exactly ten years since the first version of Bexec was released. Version 0.1 was uploaded to vim.org on Januari 30th of 2007. That makes about one release per year on average for Bexec ;-) Perhaps it’s time for v1.0 after all this time…
The text of all posts on this blog, unless specificly mentioned otherwise, are licensed under this license.
